
[Paper Reading] Beyond Single Items: Exploring User Preferences in Item Sets with the Conversational Playlist Curation Dataset (2023)
by: Arun Tejasvi Chaganty, Megan Leszczynski, Shu Zhang, Ravi Ganti, Krisztian Balog, Filip Radlinski

With recent widespread access to ChatGPT and Bard. a common question is: what are they good for? My previous post was looking at the human experience versus algorithmic performance of AI. In both cases, we need a clear definition of the purpose or task at hand. It’s also a core aspect of Authorial Leverage work (and science, in general) to define the thing that you are trying to accomplish with AI.
This paper has a very thorough end-to-end process from identifying a task that humans could use help with, like curating a music playlist, and building a model that can both process Natural Language and music (at the song level). Basically, can you develop a conversation agent that is good at recommending music— a “Conversational Recommender System.” (Famously, Netflix had the $1 million prize back in 2000’s in improving their Recommender System, which was not conversational).
(In another post, I’ll explain the difference between a Large Language Model (LLM), and a dialog model (GPT3 vs ChaptGPT)— they are generally the same thing, but the inputs/outputs are slightly different, in that dialog LLM’s are additionally given conversation history as inputs.)
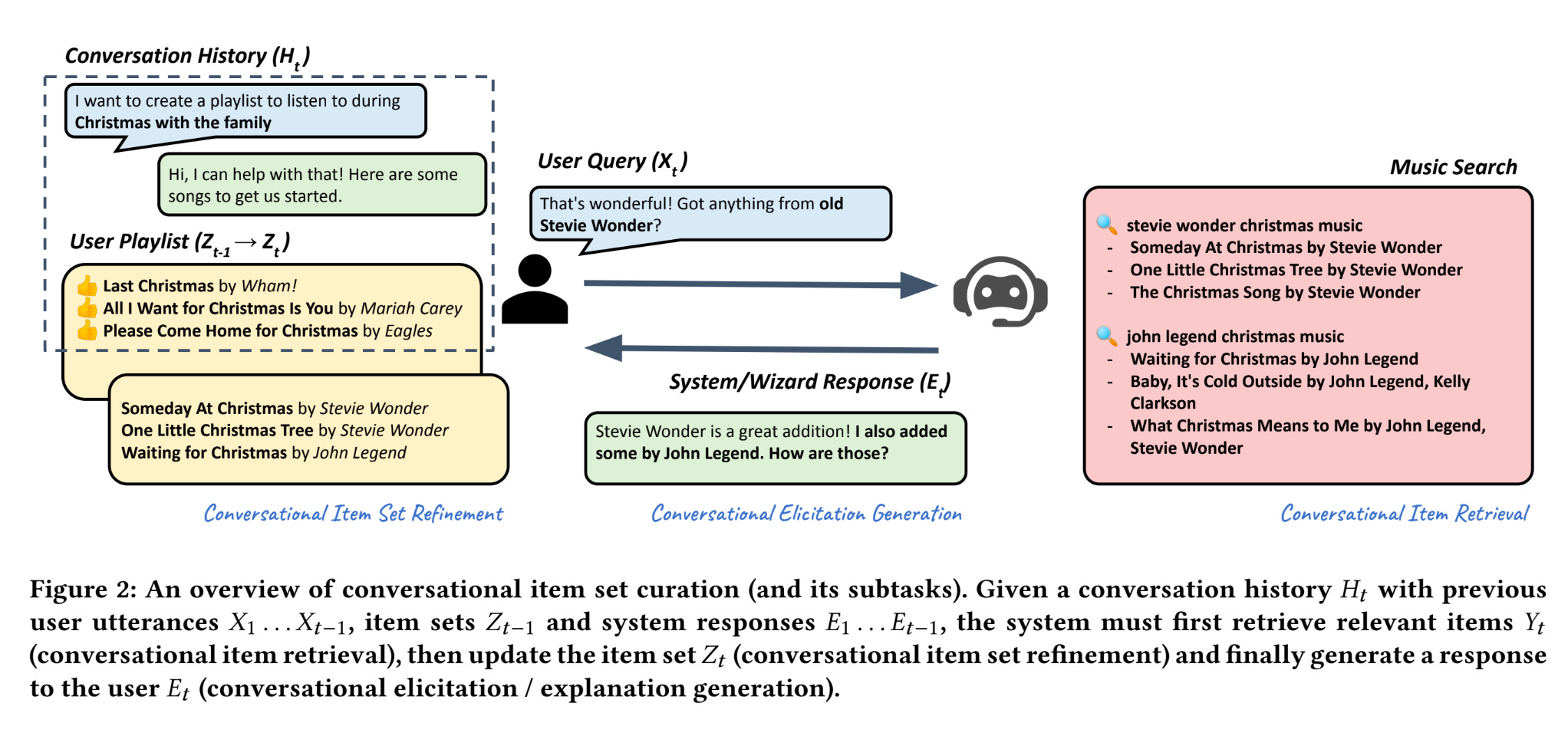
The paper describes 4 aspects of the Conversational Recommender System:
Conversational item set curation (CIsC)
Conversational Item Retrieval (CIRt)
Conversational Item Set Refinement (CIsR)
Conversational Elicitation / Explanation Generation (CEEG)
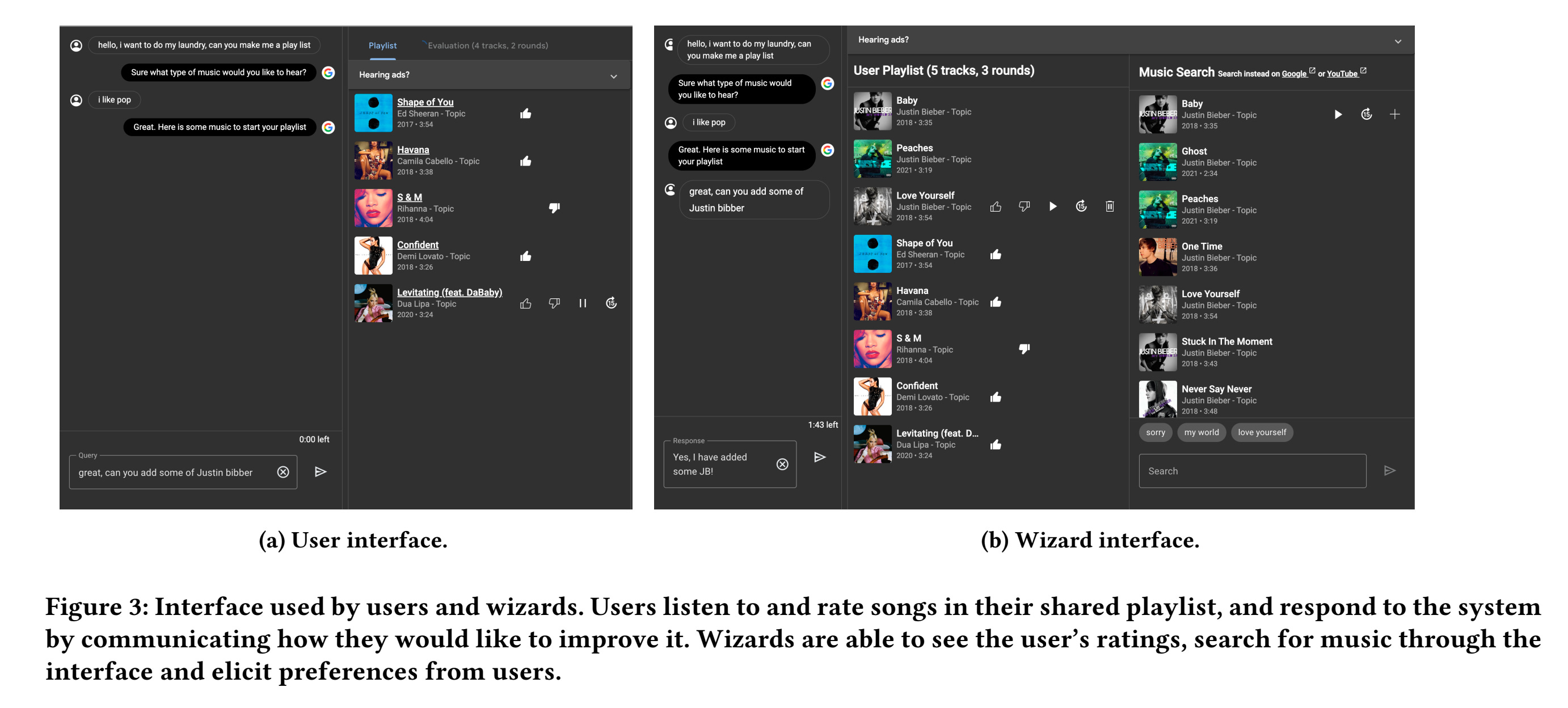
To achieve this, they took a few steps (from the Methodology section):
define the task - described above.
acquire data - this was done through crowdsourcing participants in a Wizard of Oz interaction (see image above).
post-process the data - whether naturally occurring or crowdsourced, there’s almost always some quirks in the data that need handling.
dataset analysis - they had 917 conversations that were randomly split into development and test sets, also performing some qualitative analysis.
train model - they describe 3 canonical retrieval modeling approaches: sparse retrieval, dense retrieval, and query rewriting.
Model implementation. We use a shared encoder for f and g initialized either from a pre-trained T5 1.1-Base checkpoint [40] or a T5 1.1-Base checkpoint that has been further pre-trained on retrieval tasks using the Contriever objective [19]. We then fine-tune the encoder on the CPCD development set for 1,000 steps using Adafactor [41] with a batch size of 512 and a constant learning rate of 1e-3 (further fine-tuning led to overfitting). We denote these methods as DE▷CPCD and Contriever▷CPCD respectively. (for dense retrieval)
Results
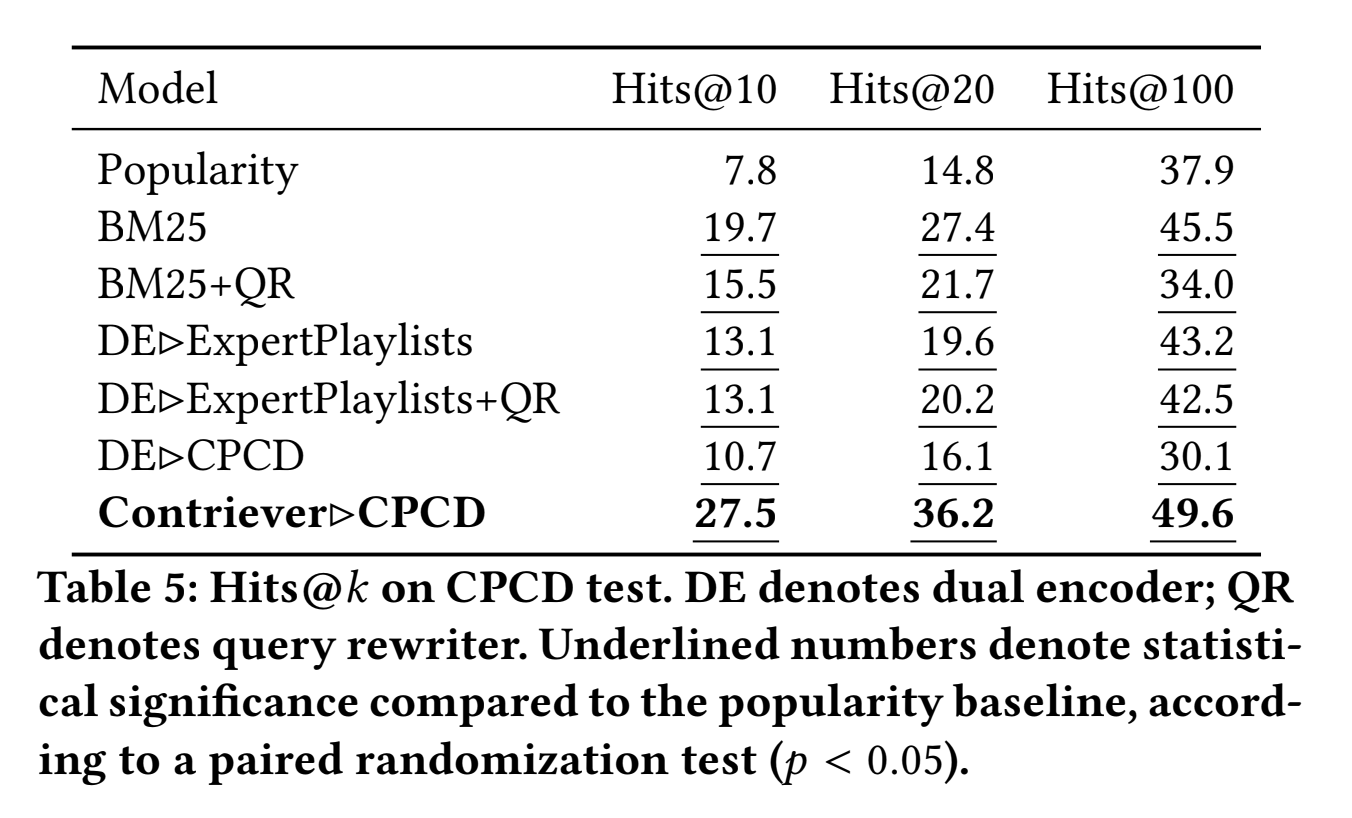
There were interesting discoveries in the evaluation and results section as well (image above). In addition to the paper, you can find the dataset here: https://github.com/google-research-datasets/cpcd

Abstract
Users in consumption domains, like music, are often able to more efficiently provide preferences over a set of items (e.g. a playlist or radio) than over single items (e.g. songs). Unfortunately, this is an underexplored area of research, with most existing recommendation systems limited to understanding preferences over single items. Curating an item set exponentiates the search space that recommender systems must consider (all subsets of items!): this motivates conversational approaches-where users explicitly state or refine their preferences and systems elicit preferences in natural language-as an efficient way to understand user needs. We call this task conversational item set curation and present a novel data collection methodology that efficiently collects realistic preferences about item sets in a conversational setting by observing both item-level and set-level feedback. We apply this methodology to music recommendation to build the Conversational Playlist Curation Dataset (CPCD), where we show that it leads raters to express preferences that would not be otherwise expressed. Finally, we propose a wide range of conversational retrieval models as baselines for this task and evaluate them on the dataset.
Link to paper: https://arxiv.org/abs/2303.06791