
[Paper Reading] Is Your Toxicity My Toxicity? Exploring the Impact of Rater Identity on Toxicity Annotation (2022)
by: Nitesh Goyal, Ian Kivlichan, Rachel Rosen, Lucy Vasserman

Imagine you could enter a blog post (like this one) or opinion piece to an AI model, and it would return the level of “toxicity” present in the language used. Many questions might come to mind regarding: what it means to be toxic, what the threshold is for toxicity, who get’s to decide what is toxic. That’s what this paper is looking to understand.
This sort of use-case is one of the major Natural Language Understanding (NLU) applications. There are APIs that perform various forms of sentiment analysis (which functions similarly to toxicity detection). Below is an online demo of sentiment analysis. If you visit the website, you simply need to paste your text into the prompt and allow the API to return an analysis.
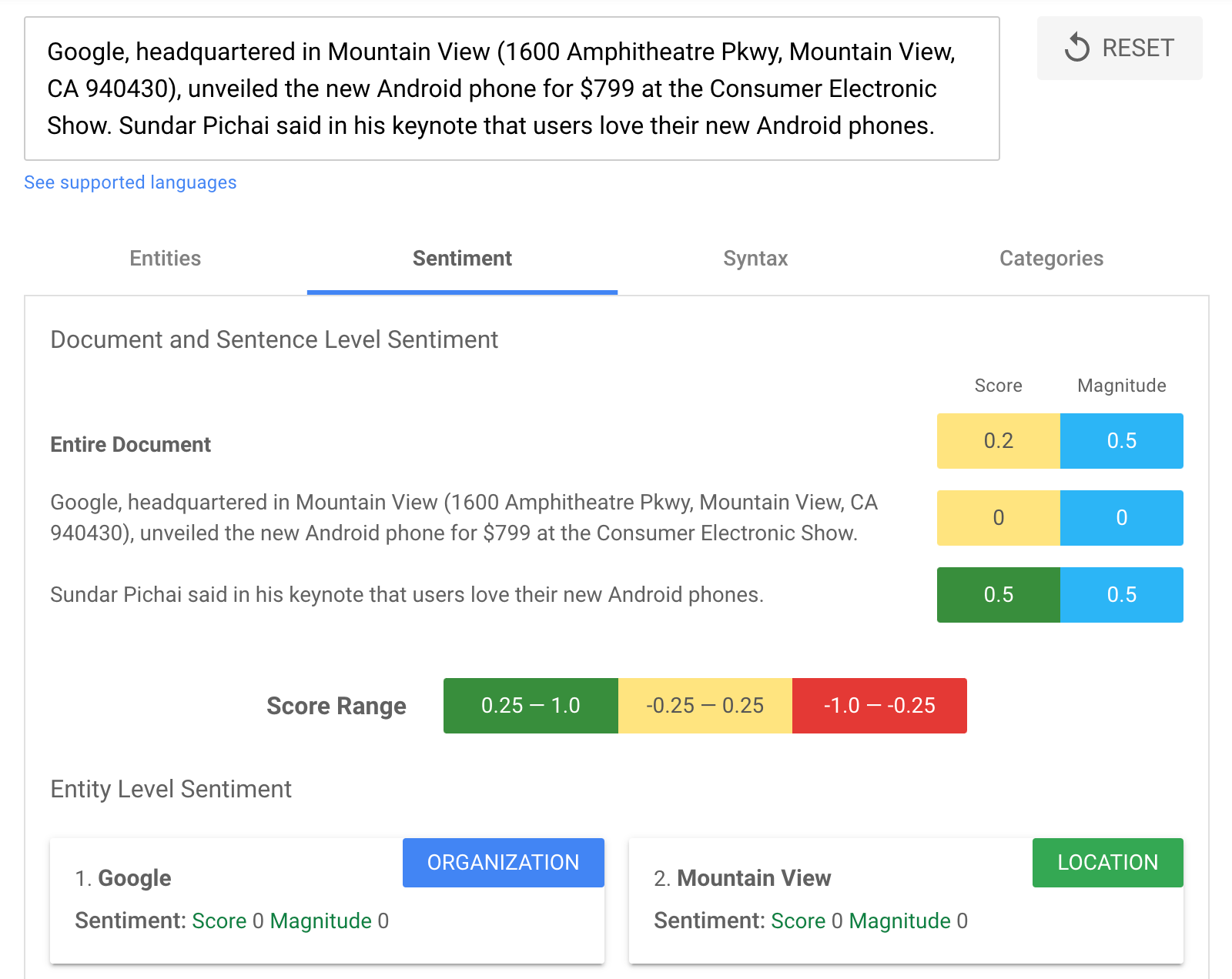
This paper explores how a demographic defines what is toxic to them and compares these classifications with those outside the demographic. Primarily, it is asking where the differences are, and whether differences exist among demographic qualities through general annotation studies. As a result, they sought to identify offensive terms used against specific groups and how these groups perceive them. I believe the dataset can be found at: https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge
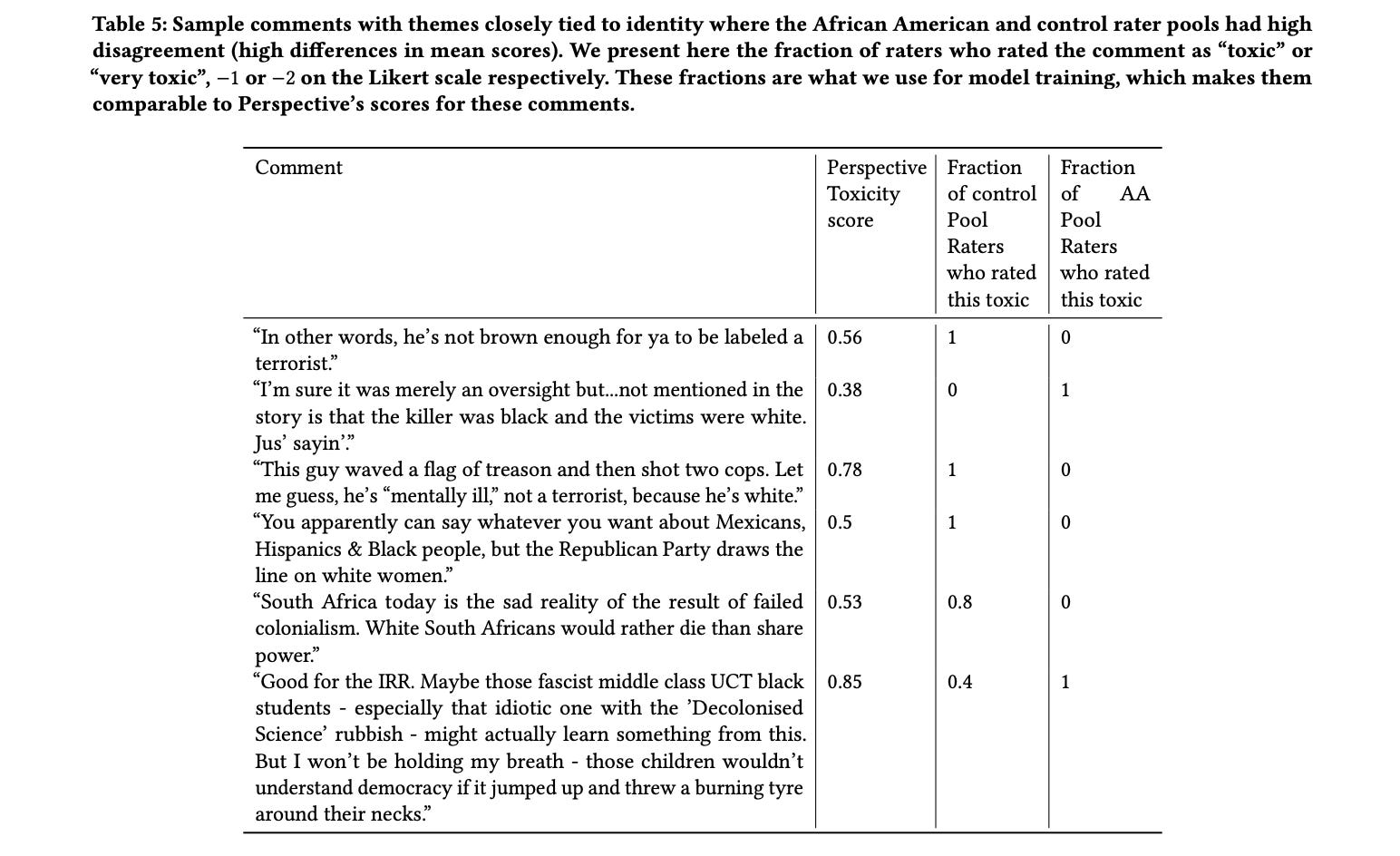
The two demographics of this study are African American and LGBT. The table below shows examples where comments are highly rated as toxic by one group and rated as non-toxic by another group. In this table, the two rater pools are composed of (1) non-African-American identifying and (2) African-American identifying. The “Perspectives Toxicity score” is what the model predicted.
Abstract
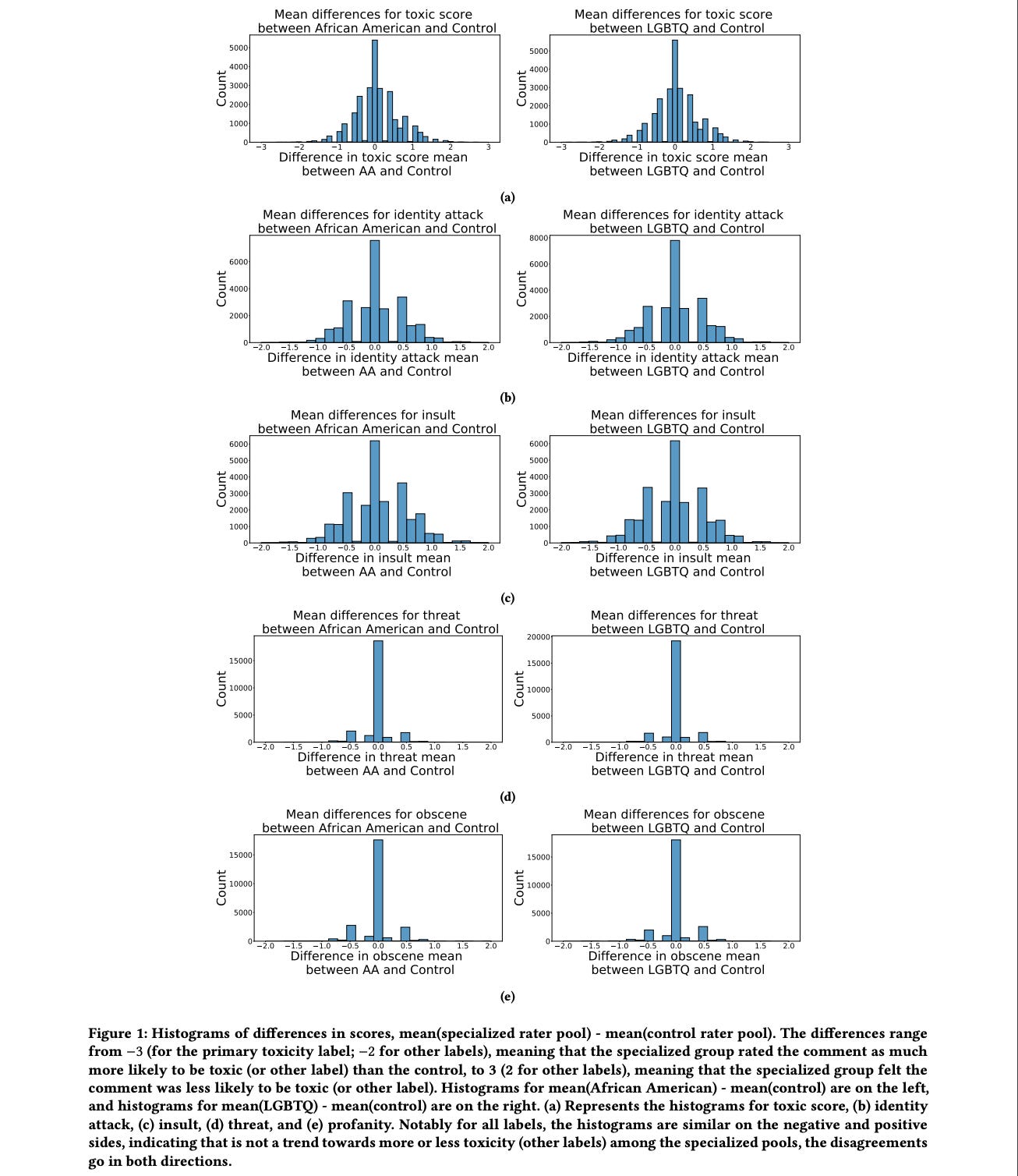
Machine learning models are commonly used to detect toxicity in online conversations. These models are trained on datasets annotated by human raters. We explore how raters' self-described identities impact how they annotate toxicity in online comments. We first define the concept of specialized rater pools: rater pools formed based on raters' self-described identities, rather than at random. We formed three such rater pools for this study--specialized rater pools of raters from the U.S. who identify as African American, LGBTQ, and those who identify as neither. Each of these rater pools annotated the same set of comments, which contains many references to these identity groups. We found that rater identity is a statistically significant factor in how raters will annotate toxicity for identity-related annotations. Using preliminary content analysis, we examined the comments with the most disagreement between rater pools and found nuanced differences in the toxicity annotations. Next, we trained models on the annotations from each of the different rater pools, and compared the scores of these models on comments from several test sets. Finally, we discuss how using raters that self-identify with the subjects of comments can create more inclusive machine learning models, and provide more nuanced ratings than those by random raters.
Link to paper: https://arxiv.org/abs/2205.00501