
[Paper Reading] What We Can't Measure, We Can't Understand: Challenges to Demographic Data Procurement in the Pursuit of Fairness (2021)
by: McKane Andrus, Elena Spitzer, Jeffrey Brown, Alice Xiang


In an age of Generative AI hype, I’m interested in the emerging scholarship around Subjective Alignment. AI Alignment is about how well AI adheres to human process and intention. This year, I’ve been working on a couple projects on subjectivity and a couple projects on authorial leverage, both were major aspects of my dissertation. A main challenge of aligning subjective matters is representing the ground truth when there isn’t one right answer. Much of the field assumes that there is a right answer (spam or not spam), but many decisions have many correct answers, often depending on context as well as other factors. Even for clear classification tasks like we see in the popular MNIST dataset (below), there are subjective cases (like, when a 3 also looks like a 9).

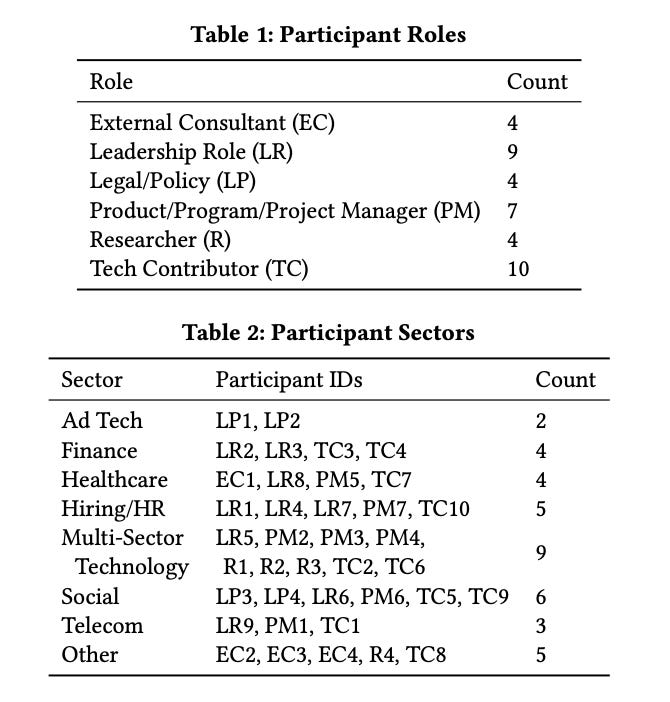
This paper highlights challenges in identifying bias, as it is often only implicitly represented in our data. Downstream, we can observe bias in model outputs, but are less able to automate the detection of bias as a result of not having explicit demographic attributes. Participants identified barriers and tensions between privacy and fairness, and the study concludes with 6 core challenges:
Deficient Standards: How many choices of gender?
Difficulties with Granular Representations: How to classify qualitative answers for an intake form?
Prioritization: What categories should be focused on?
Regional Differences: Which legal system should we adhere by?
Convenience: How do we find participants willing to identify sensitive information?
Implications: How do we work with or around bias?
Abstract
As calls for fair and unbiased algorithmic systems increase, so too does the number of individuals working on algorithmic fairness in industry. However, these practitioners often do not have access to the demographic data they feel they need to detect bias in practice. Even with the growing variety of toolkits and strategies for working towards algorithmic fairness, they almost invariably require access to demographic attributes or proxies. We investigated this dilemma through semi-structured interviews with 38 practitioners and professionals either working in or adjacent to algorithmic fairness. Participants painted a complex picture of what demographic data availability and use look like on the ground, ranging from not having access to personal data of any kind to being legally required to collect and use demographic data for discrimination assessments. In many domains, demographic data collection raises a host of difficult questions, including how to balance privacy and fairness, how to define relevant social categories, how to ensure meaningful consent, and whether it is appropriate for private companies to infer someone's demographics. Our research suggests challenges that must be considered by businesses, regulators, researchers, and community groups in order to enable practitioners to address algorithmic bias in practice. Critically, we do not propose that the overall goal of future work should be to simply lower the barriers to collecting demographic data. Rather, our study surfaces a swath of normative questions about how, when, and whether this data should be procured, and, in cases where it is not, what should still be done to mitigate bias.
Paper Link: https://arxiv.org/pdf/2011.02282.pdf