
Paper Reading: What Will it Take to Fix Benchmarking in Natural Language Understanding? (2020)
by: Samuel R. Bowman, George E. Dahl


This paper highlights issues for evaluating Natural Language performance in ML. In general, for ML training, the goal is to “lower the loss.” As soon as a model (perhaps in the language space) is able to lower the loss, this is seen as an improvement. TensorFlow has a cool playground that visualizes how this works.
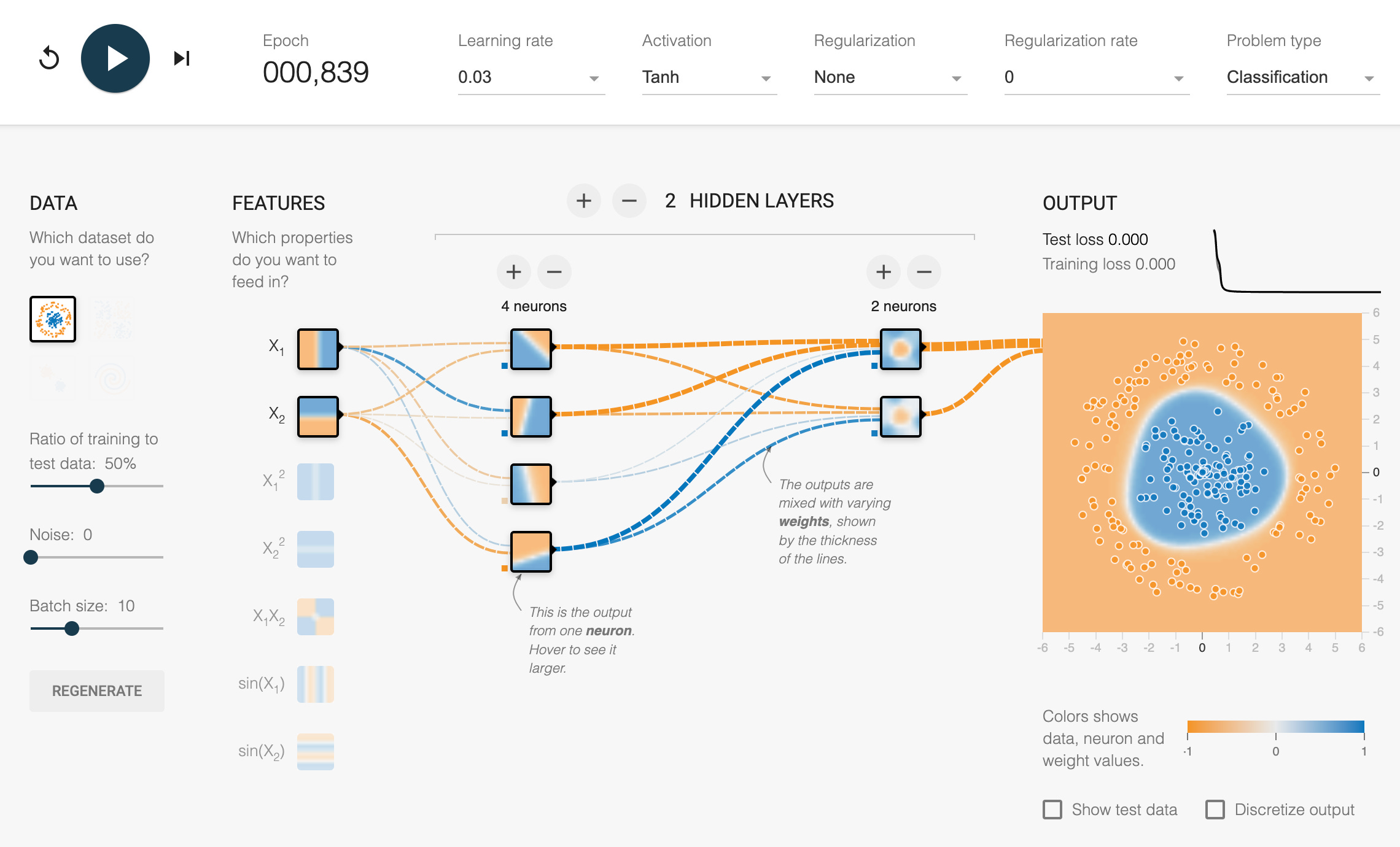
When applying a model for real-world use, simply lowering the loss isn’t full proof and often insufficient for certain types of tasks. For example, none of the commercial virtual assistants directly use language models for Natural Language Generation. Finding quality datasets to overcome this is a major challenge, because models will perform well on biased data, especially if they are being evaluated by data with the same bias (often from the same corpus). This paper outlines typical types of benchmark datasets:
Naturally-Occurring - www.yelp.com/dataset
Expert-Authored - www.atticusprojectai.org/cuad
Crowdsourcing - storage.googleapis.com/openimages/web/
Adversarial Filtering - github.com/google-research-datasets/cats4ml-2021-dataset
Abstract
Evaluation for many natural language understanding (NLU) tasks is broken: Unreliable and biased systems score so highly on standard benchmarks that there is little room for researchers who develop better systems to demonstrate their improvements. The recent trend to abandon IID benchmarks in favor of adversarially-constructed, out-of-distribution test sets ensures that current models will perform poorly, but ultimately only obscures the abilities that we want our benchmarks to measure. In this position paper, we lay out four criteria that we argue NLU benchmarks should meet. We argue most current benchmarks fail at these criteria, and that adversarial data collection does not meaningfully address the causes of these failures. Instead, restoring a healthy evaluation ecosystem will require significant progress in the design of benchmark datasets, the reliability with which they are annotated, their size, and the ways they handle social bias.
Conclusion
Benchmarking for NLU is broken. We lay out four major criteria that benchmarks should fulfill to offer faithful, useful, and responsible measures of language ability. We argue that departing from IID evaluation (as is seen with benchmark datasets collected by adversarial filtering) does not help to address these criteria, but lay out in broad strokes how each criterion might be addressed directly. Nonetheless, important open research questions remain. Most centrally, it is still unclear how best to integrate expert effort into crowdsourced data collection, and we do not yet see a clear institutional model by which to ensure that bias metrics are built and used when they are most needed.
Paper: https://arxiv.org/abs/2104.02145
As I think about AI research standards and benchmarks, I feel both “Data Sheets” and “Model Cards” (which are basically design docs for data and ML respectively) are two widely discussed practices in the community that I can post about next.